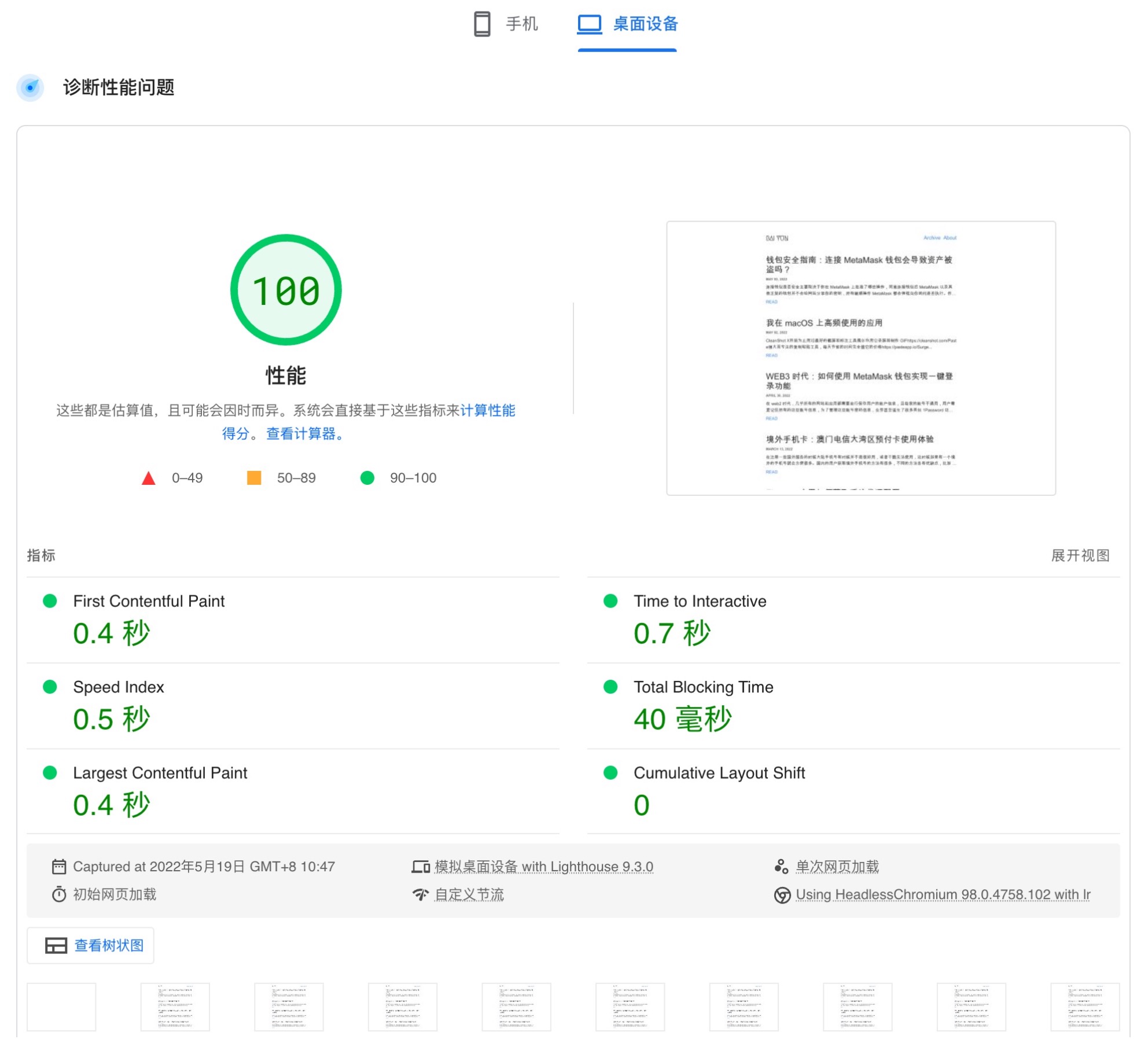
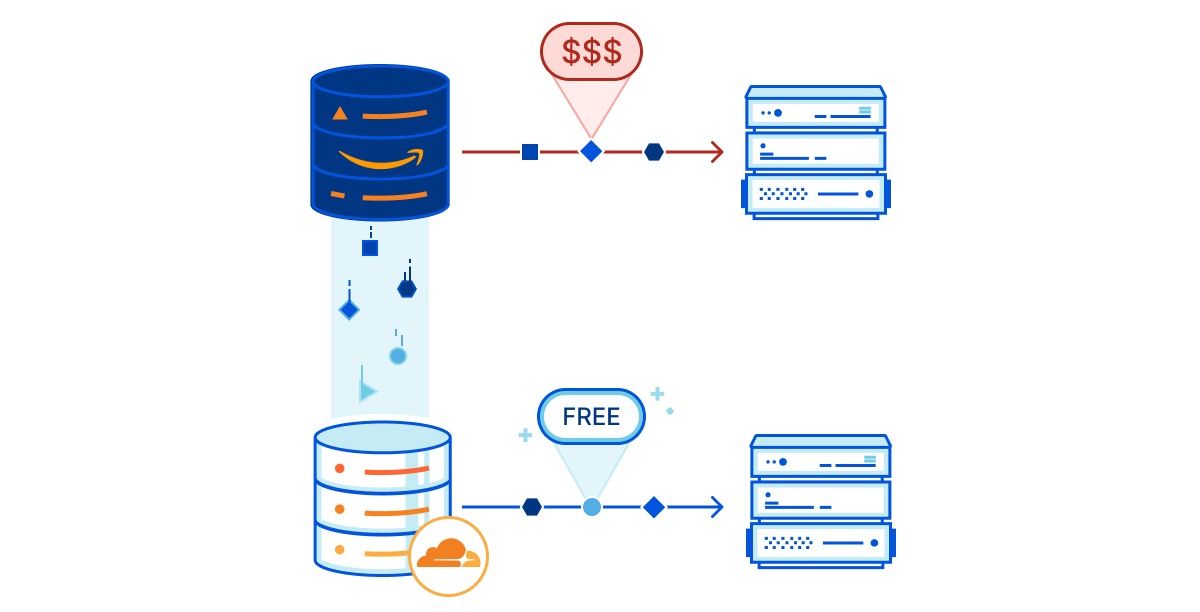
传统的 IPTV 需要使用运营商提供的 IPTV Box 连接电视才能观看,这种方案有几个缺点:
- 客厅如果只有一个网口就得在上网和 IPTV 之间二选一
- 每次看 IPTV 必须切换视频信号到 IPTV Box,稍微麻烦一些
- 必须忍受 IPTV Box 的 UI/UX
- 客厅电视没有空闲的 HDMI 端口可用(已经连接了多个设备,例如游戏机、其他电视盒子)
如果你想解决这些问题。网络上通常有很多术语,令人眼花缭乱,例如 IPTV 组播转单播、IPTV 单线复用、光猫超级管理员密码之类的概念。
本文经过实际测试摸索,找到一条相对简单高效的方案,大概只需要10分钟时间即可配置完毕。
为什么要开 IPTV
经常听到一种说法:“现在都没人看电视了”,在抖音之类的短视频大行其道,人手一个智能手机的现状下,确实,现在包括很多老年人在内一年都开不了几次电视。
那为什么要折腾开通 IPTV 呢?从我的角度来说主要有以下几点:
- 画质:IPTV 码率相对较高,1080p(H264) 一般在 8 Mbps 左右,4K(HEVC 50fps HDR) 一般在 20-30Mbps 左右,显著高于国内大部分流媒体平台
- 延迟:IPTV 走电信专用内网,直播延迟相对较低,尤其是组播协议
- 直播:各种体育赛事、大型年度直播之类的直接看 CCTV 或者对应频道是最省事的
对我来说主要观看的是 CCTV 5、CCTV 16 这类体育频道,虽然有广告,但是相对来说明显画质和延迟要比国内流媒体平台好不少,并且不用每家都开会员。
相比腾讯优酷爱奇艺之类的体育会员动辄几十块一个月,IPTV 一个月 10 块钱,对于轻度用户来说性价比可以说很好了。
前置条件
- 已开通 IPTV 服务,如果你已经在用融合宽带套餐,每个月加 10 块钱就可以
- 光猫和路由器放在一起,可以从光猫接两根网线到路由器
- 光猫有单独标识的 ITV 端口
- 局域网内有可以安装 docker 镜像的设备(例如 NAS)或者你有其他办法可以在局域网内部署 https://github.com/stackia/rtp2httpd
- OpenWrt 软路由或者其他支持自定义 dhcp client hostname 和 option 的路由器
前置测试
我的光猫是在安装宽带时就让电信工作人员设置了桥接模式加路由器拨号,除此以外没有改过网络接口相关设置。也就说你不需要超级管理员账密。
将光猫 ITV 口接一根网线连到电脑,在电脑网络设置里手动设置此连接的 IP(指定为 192.168.1.1xx)具体 IP 段一般和光猫背面展示的控制台地址一致。本文后面以此 IP 段示例。
网关指定为 192.168.1.1
然后使用 VLC 播放器播放组播地址,可以从以下项目找具体地址:
https://github.com/FHZDCJ/Zhejiang_Telecom_IPTV/blob/main/Zhejiang_Multicast/Zhejiang_Telecom_IPTV.m3u
格式:rtp://233.xxx.xxx.xxx:5140,如果可以正常播放组播源,则继续后面的步骤。
在执行此测试的时候建议关闭 Wi-Fi 和 surge 之类的工具。确保所有请求直接通过网线发给光猫的 ITV 口。
组播转单播
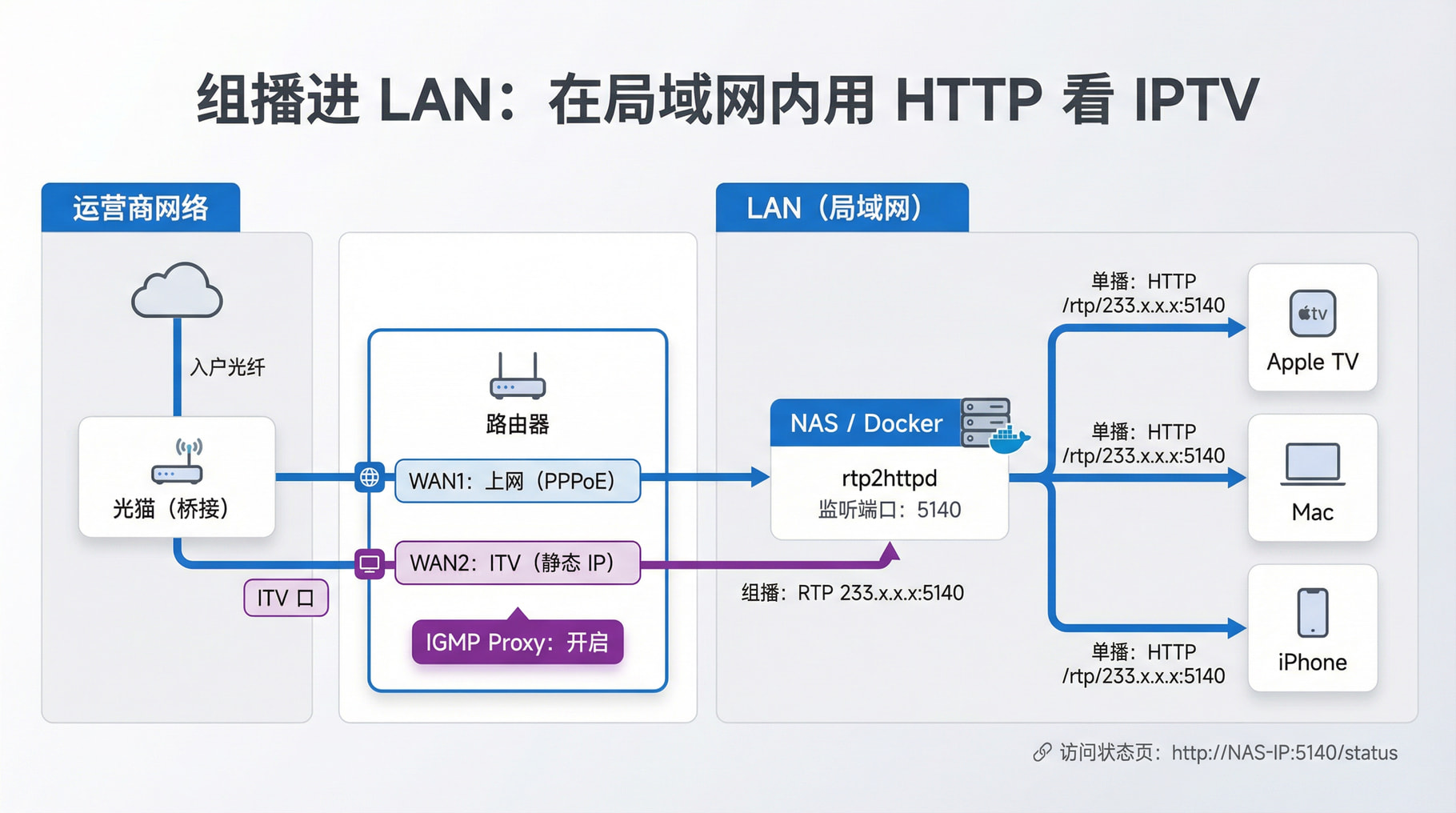
如果前面的测试通过,说明你当前的网络条件可以正常播放组播源信号。
接下来为了实现在局域网内任意设备观看 IPTV,需要将组播信号(通常是 rtp 协议)转为单播信号(http 协议)。
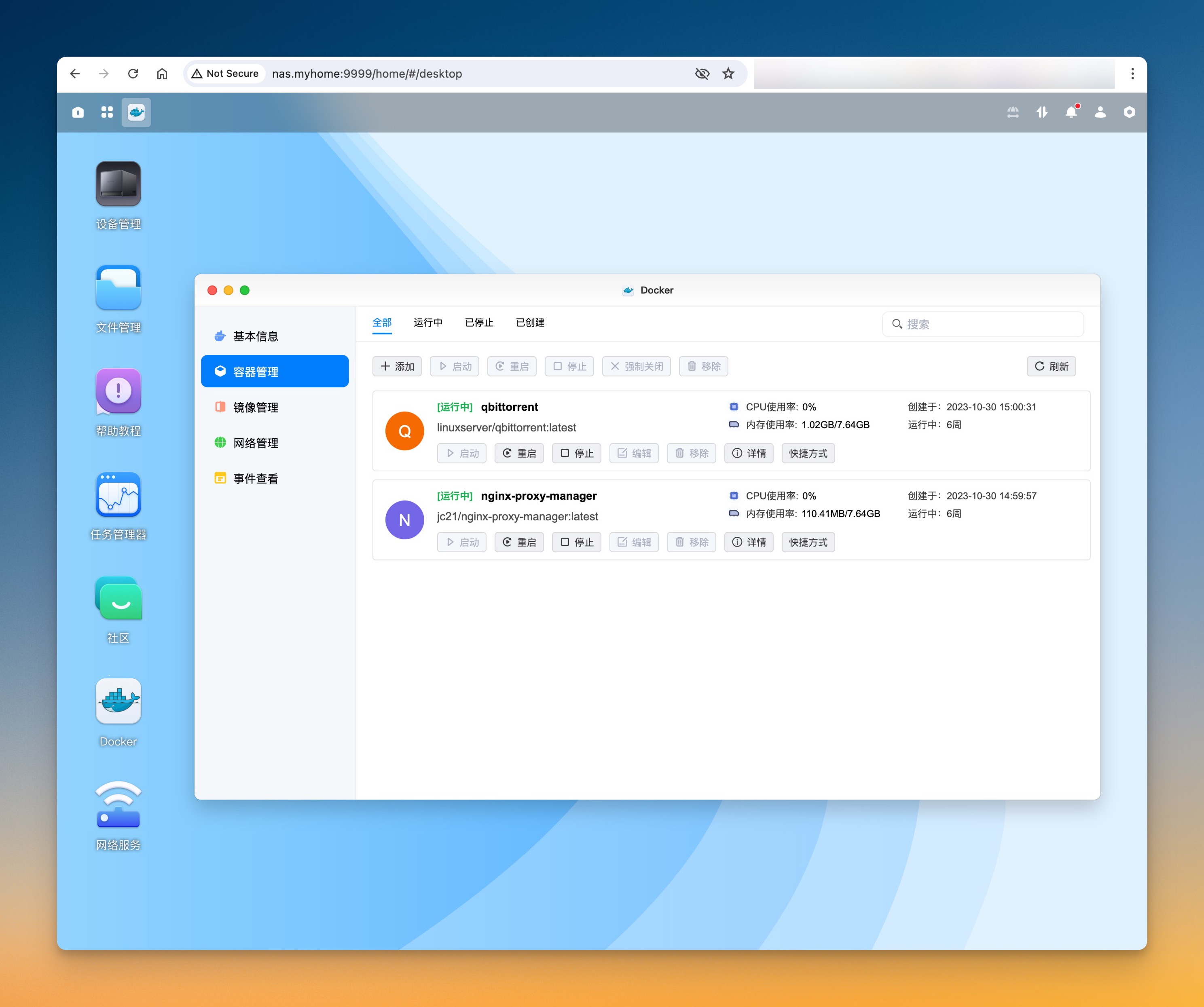
首先需要在局域网内正常部署 https://github.com/stackia/rtp2httpd 服务。
我是直接在 NAS 上通过 Docker Compose 部署的,配置如下:
services:
rtp2httpd:
image: ghcr.io/stackia/rtp2httpd:latest
container_name: rtp2httpd
network_mode: host
command: --noconfig --verbose 2 --listen 5140 --maxclients 20
待你可以正常访问 http://NAS-IP:5140/status 之后再进行下一步。
将光猫 ITV 口连接到路由器的第二个 WAN 口(第一个 WAN 口用于正常上网),这一步的主要目的是实现在正常上网的这个 LAN(局域网) 里面通过 HTTP 单播源观看 IPTV。
我用的是 Unifi 路由器,直接在控制台新建一个 WAN 口,关联刚才连接 ITV 口的端口,同时勾选 IGMP proxy 开关(这个很关键),选择静态 ip。
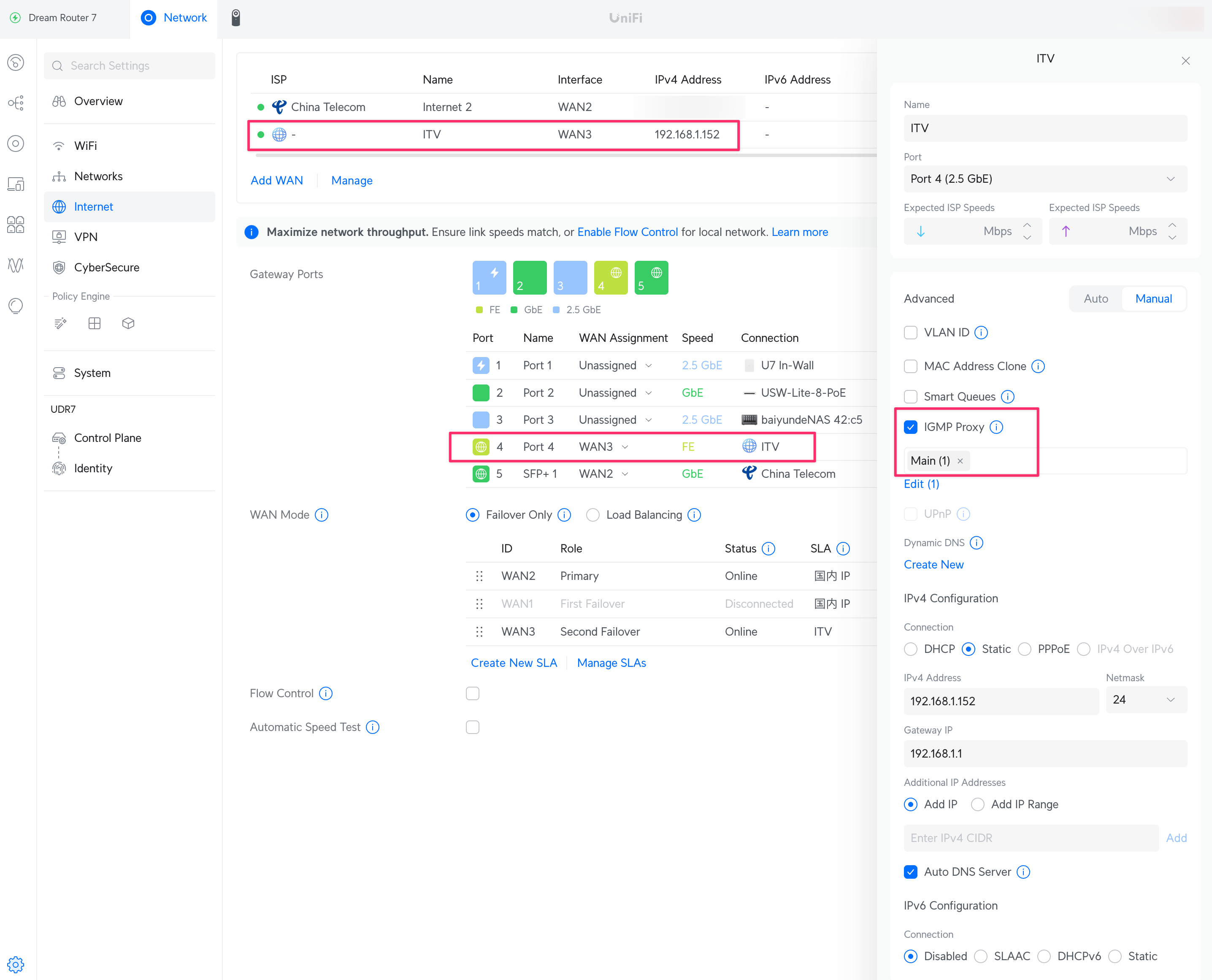
此时在 VLC 里打开 rtp2httpd 格式的单播信号源地址:
http://192.168.10.20:5140/rtp/239.xxx.xxx.xxx:5140
这里 192.168.10.20 是我的 NAS 地址,里面用 docker 部署了rtp2httpd(host 网络模式,默认绑定在 5140 端口),239.xxx.xxx.xxx 是具体 IPTV 频道的组播地址。
正常情况下这里就可以正常观看了。
最后,为了方便切换所有可观看的频道,可以将这里的 m3u 文件进行修改:
https://github.com/FHZDCJ/Zhejiang_Telecom_IPTV/blob/main/Zhejiang_Multicast/Zhejiang_Telecom_IPTV_ONLINE_LOGO.m3u
替换里面的链接为 rtp2httpd 格式,以下是替换后的示例:
#EXTM3U
#EXTINF:-1 tvg-id="CCTV1" tvg-name="CCTV1" group-title="央视",CCTV1综合
http://192.168.10.20:5140/rtp/233.xxx.xxx.xxx:5140
#EXTINF:-1 tvg-id="CCTV2" tvg-name="CCTV2" group-title="央视",CCTV2财经
http://192.168.10.20:5140/rtp/233.xxx.xxx.xxx:5140
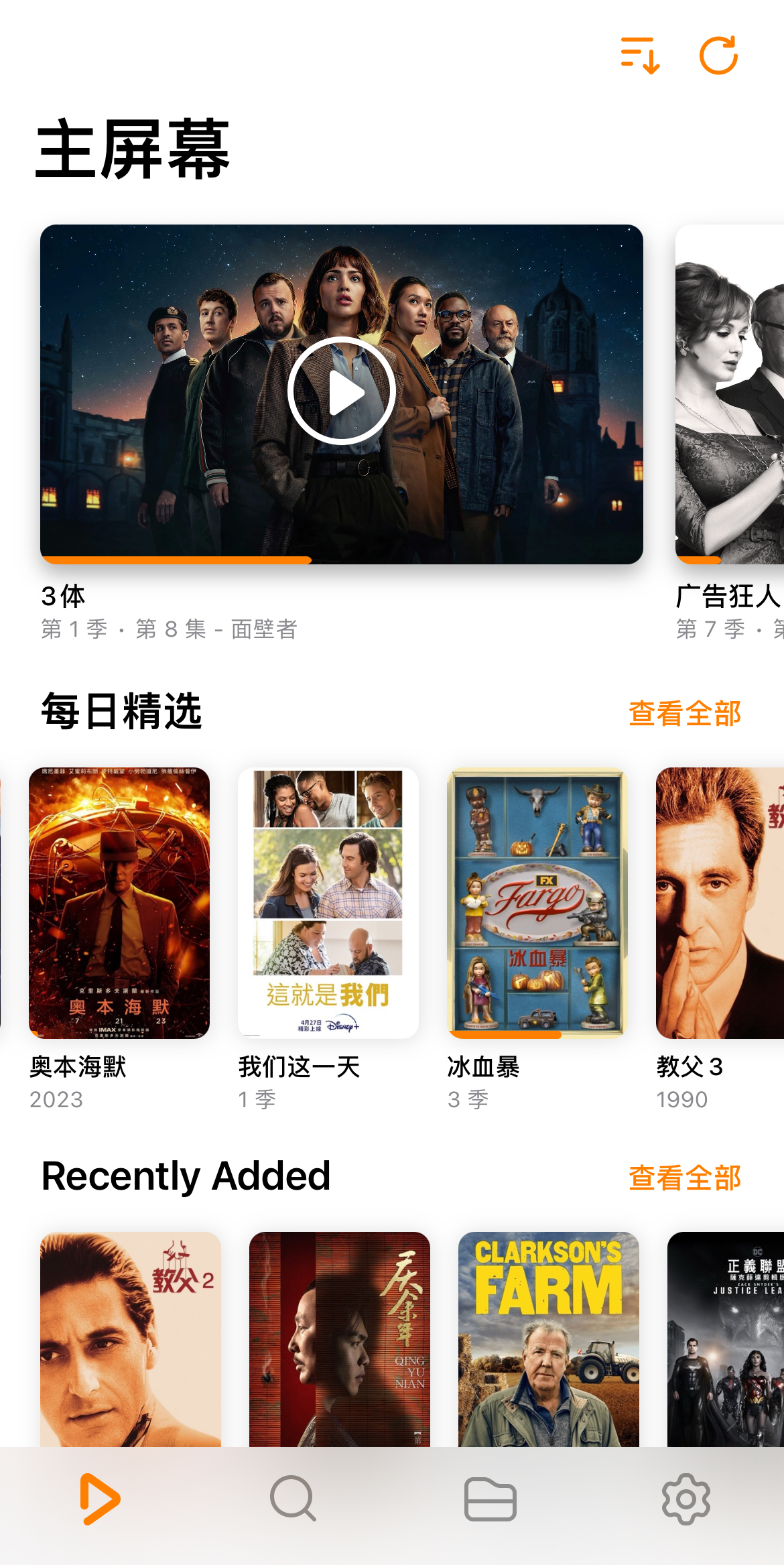
将修改后的 m3u 文件导入到 APTV 之类的软件即可在 Apple TV、Mac、iPhone 等局域网设备观看 IPTV 频道。
原始单播信号
对于大部分用户来说,如果组播信号用起来感觉没啥问题,就不推荐折腾单播信号了,毕竟首次设置和后续维护成本还是显著增加的。并且单播的延迟和性能在高峰期可能不如组播稳定,这是它们的技术原理决定的。不存在单播就一定优于组播。
组播最大的问题是如果配置不当,可能对局域网性能造成影响,例如在观看 IPTV 的时候会给局域网内所有设备端口进行 “泛洪” 发送无意义流量包。使用运营商提供的原始单播信号可以避免这个问题。
所谓原始单播信号是指直接在局域网任意设备上使用下面这种格式的 URL 即可观看 IPTV 频道:
rtsp://115.xxx.xxx.xxx/PLTV/88888913/224/3221228078/xxx.smil
对于杭州电信来说,想要访问运营商提供的单播信号源,需要通过和 IPTV 盒子一样的认证才可以。
杭州电信的 IPTV 盒子使用 IPoE 认证,打开 IPTV 盒子的网络设置可以发现,正常通过认证的情况下可以获取到 10 开头的 IP 地址和网关地址。
要想认证通过拿到合法的 IP 和网关信息,IPTV 盒子会作为一个 DHCP Client 向运营商发送 DHCP 报文,并在报文里携带两个关键信息:
- hostname (option 12) 这个值是盒子的STB ID,具体格式见下方。
- vendorid (option 60) 这个值是盒子内部使用 IPoE 账密 + 其他逻辑计算生成后发送的,需要抓包获取
IPoE (IP over Ethernet) 是一种直接在以太网(Ethernet)上承载 IP 数据的网络接入技术,它替代了传统的 PPPoE,通过 DHCP 动态获取 IP 地址并利用用户的物理信息(如 MAC 地址、VLAN ID)进行认证。
获取 hostname

记下盒子上的 STBID,它就是 dhcp 报文里的 option 12(hostname)
示例值:00108325090207200000B1FDF1E258FD
获取 vendorid (option 60)
这一步核心原理是抓取 IPTV 盒子开机后发送的 DHCP 报文,里面包含了盒子内部计算好的 vendorid。
抓包方式有很多种,简单的一种是直接将盒子用网线(交叉线)连接到电脑网口,电脑启动 Wireshark 捕获对应的网口,待盒子通电开机后,在 Wireshark 顶部搜索框输入 dhcp 过滤出所有 dhcp 报文。
找到对应报文找到并展开 Option: (60) Vendor class identifier,选中里面的 Vendor class identifier:,右键 copy as hex stream。
复制到的内容应当是这种格式:00001f39d35c06c5560f91e4f652a438f7bd9ad33a5972fb06e75f6f45cb4fdfb190045a51153196b05f5a7b5d5b6f699b5d5b4956975b4900000000300e89ed9c786007ee110
将其保存起来。
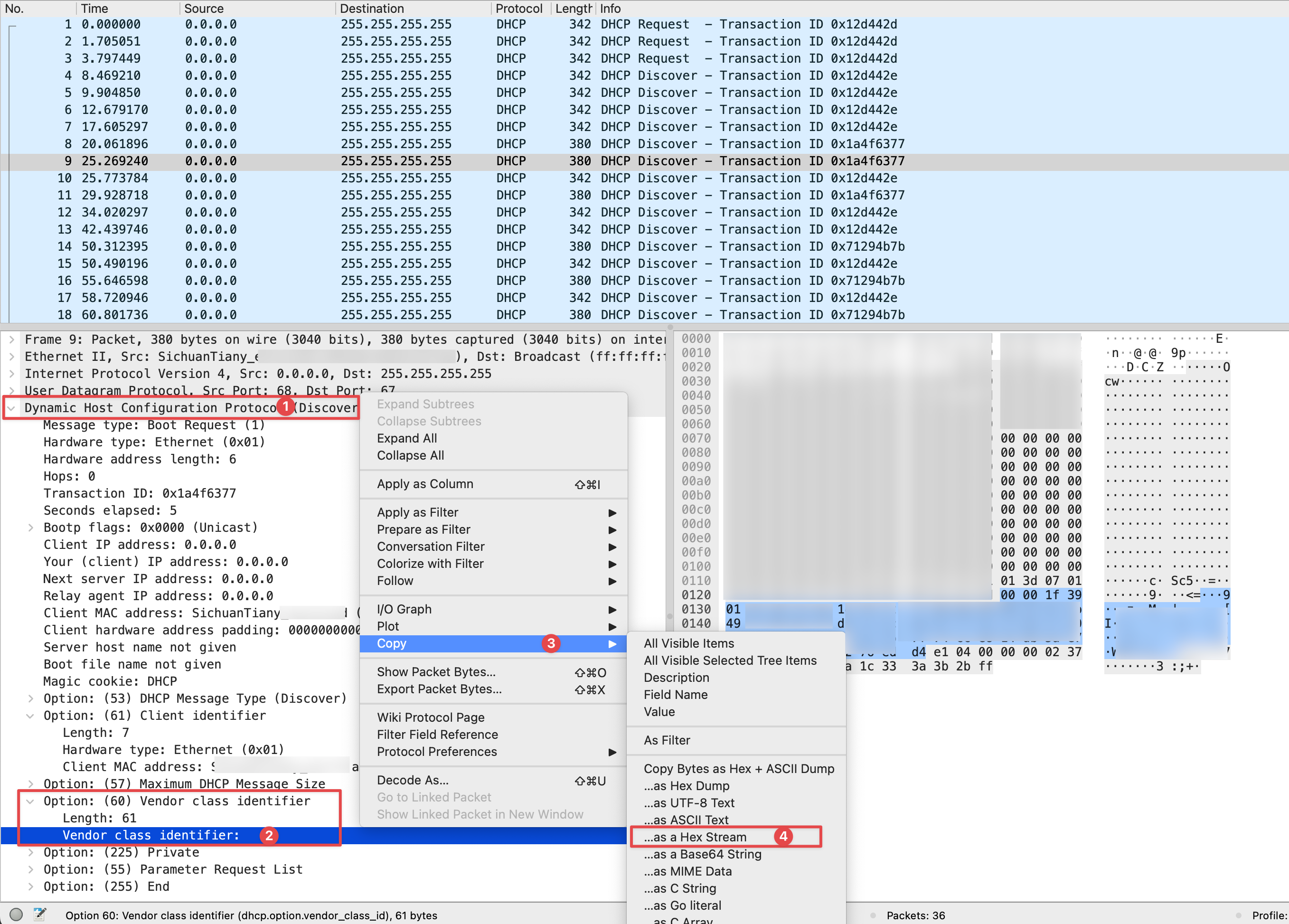
注意 DHCP 报文里的
Client MAC address要和 IPTV 盒子的 MAC 地址匹配,避免被电脑自己发出的报文干扰。
配置主路由网络接口
我的光猫 ITV 口和主路由 UDM Port 4 用网线连接。确保 Port 4 没被分配给 WAN 口。
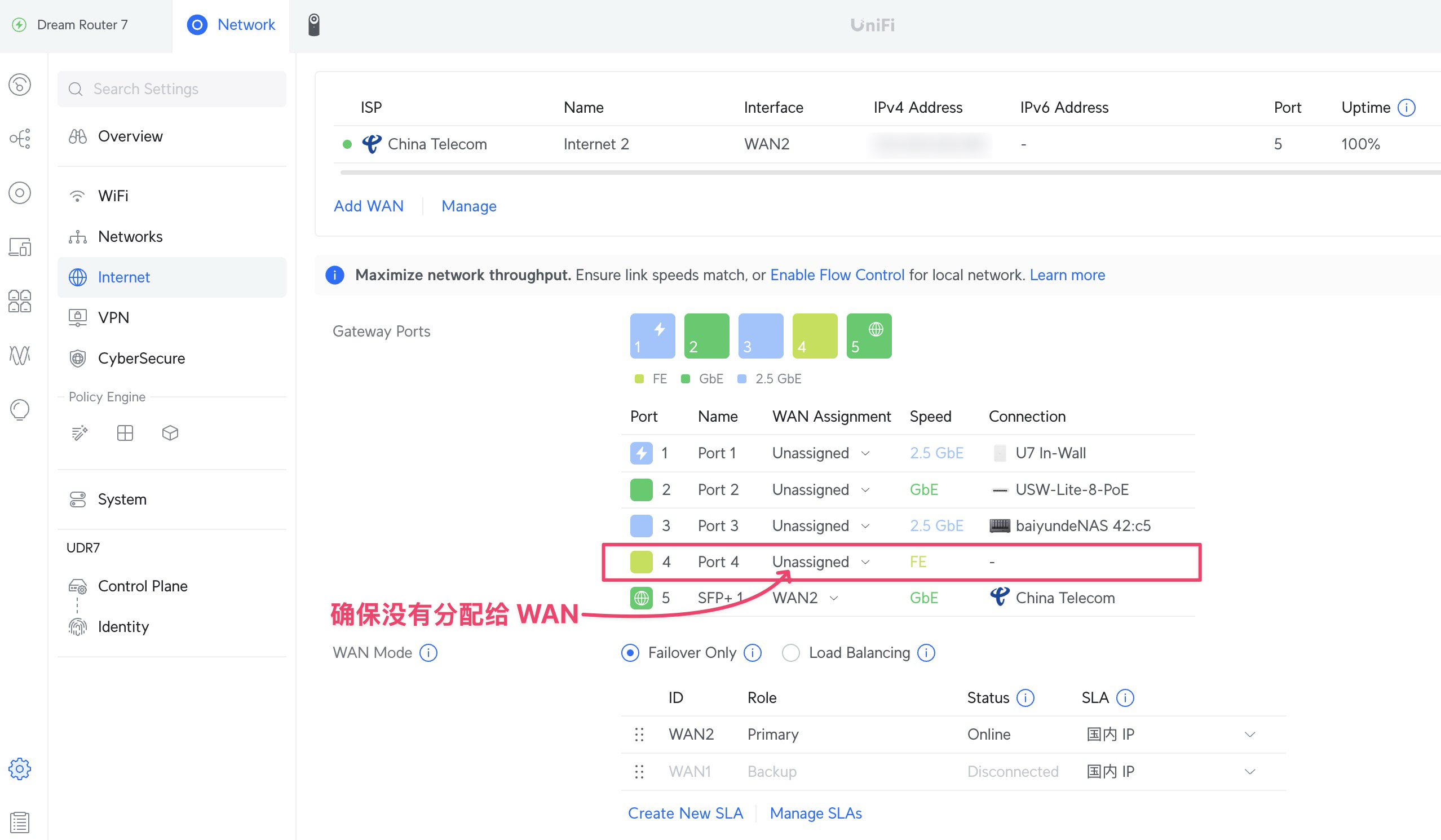
新建 IPTV VLAN
id 设置为 100,命名为 IPTV, 避免和其他 vlan id 混淆:
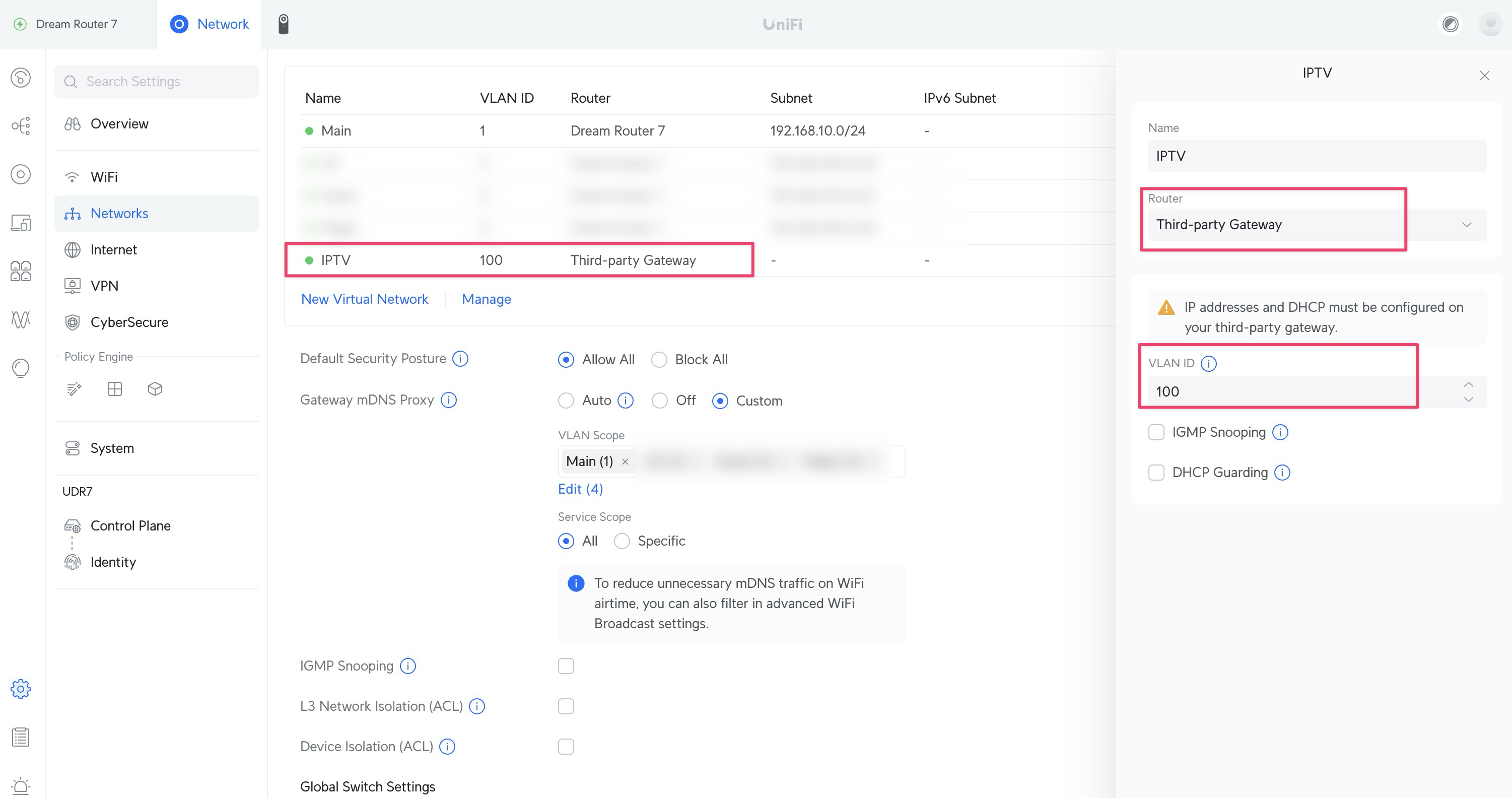
给 UDM Port 4 绑定 VLAN 100:
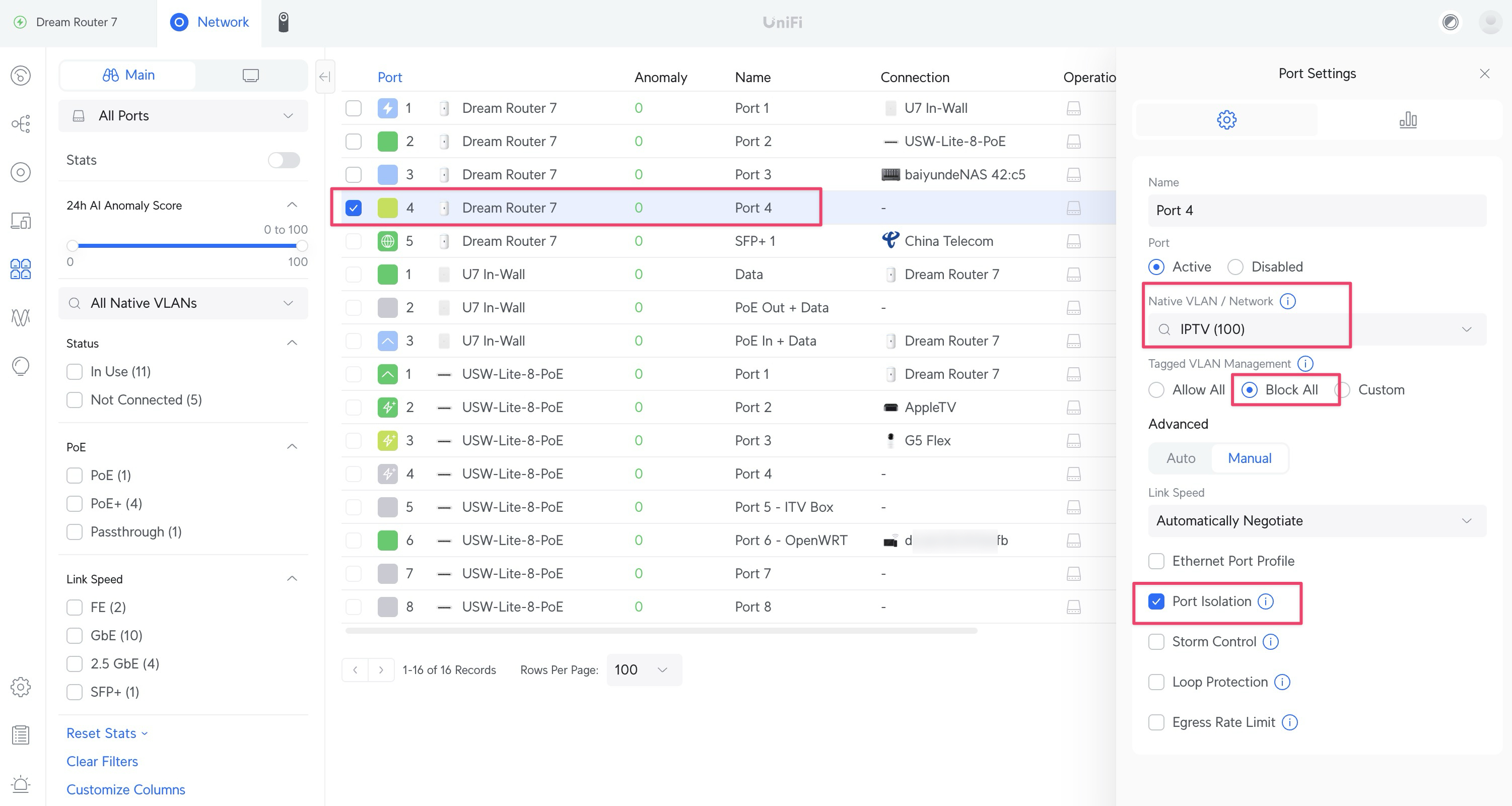
设置 OpenWrt 对应的交换机端口
我的 OpenWrt 是一个树莓派,我将其插入了客厅 USW 交换机的 Port 6,需要正确配置此端口:
Native VLAN:选择局域网主 VLAN
Tagged VLAN Management:custom
Tagged VLANs:选择前面新增的 VLAN 100
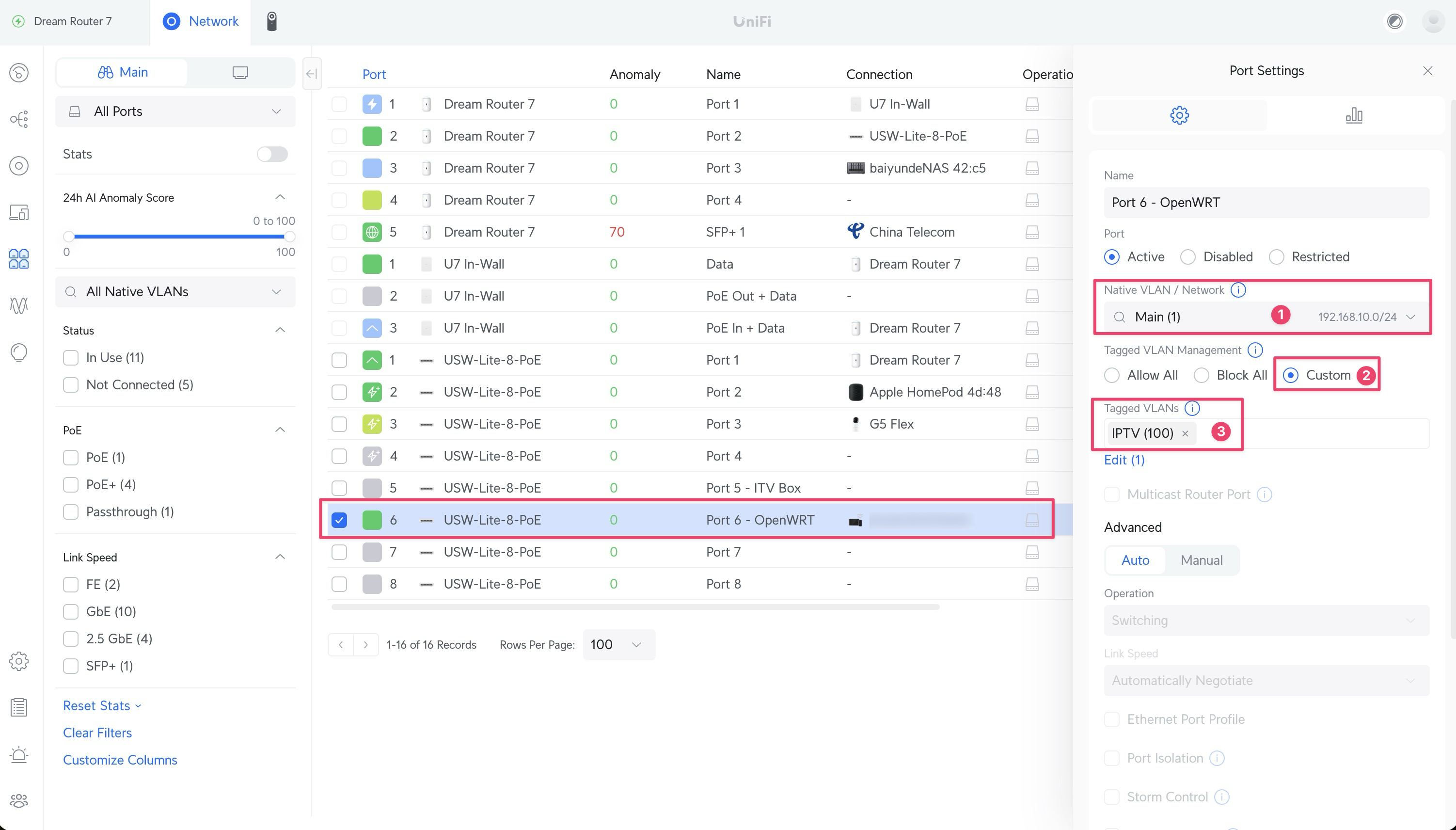
配置 OpenWrt 软路由
由于我家里的 UDM 路由器不支持设置 DHCP Client 的 hostname,所以找来找去还是找一台设备刷个 OpenWrt 最简单,我是找了家里吃灰的树莓派 4B 刷了最新稳定版 OpenWrt。
修改网络接口
新增 一个 device,一个 interface:
vim /etc/config/network
config device
option type '8021q'
option ifname 'eth0'
option vid '100'
option name 'eth0.100'
config interface 'IPTV_WAN'
option proto 'dhcp'
option device 'eth0.100'
option metric '20'
option hostname '这里替换为前面拼接获取的hostname'
option macaddr '这里替换为iptv盒子的完整mac地址'
option sendopts '60:这里替换为前面抓包拿到的vendorid'
option defaultroute '0'
修改 lan 的 IP 地址:
vim /etc/config/network
将 interface 'lan' 改为静态 IP,指定正确的局域网 IP 和网关地址。
config device
option name 'br-lan'
option type 'bridge'
list ports 'eth0'
config interface 'lan'
option device 'br-lan'
option proto 'static'
option ipaddr '主路由器局域网IP地址(没被使用的)'
option netmask '255.255.255.0'
option ip6assign '60'
option gateway '主路由器网关地址'
option metric '20'
修改 dhcp.sh 脚本
vim /lib/netifd/proto/dhcp.sh
原版:会导致 DHCP 报文发送两个 option 60
proto_run_command "$config" udhcpc \
-p /var/run/udhcpc-$iface.pid \
-s /lib/netifd/dhcp.script \
-f -t 0 -i "$iface" \
${ipaddr:+-r $ipaddr} \
${hostname:+-x "hostname:$hostname"} \
${vendorid:+-V "$vendorid"} \
$clientid $defaultreqopts $broadcast $release $dhcpopts
修改后的版本:去除了 ${vendorid:+-V "$vendorid"} 这一行,增加了 -V '' \ 这行
proto_run_command "$config" udhcpc \
-p /var/run/udhcpc-$iface.pid \
-s /lib/netifd/dhcp.script \
-f -t 0 -i "$iface" \
${ipaddr:+-r ${ipaddr/\/*/}} \
${hostname:+-x "hostname:$hostname"} \
-V '' \
$clientid $defaultreqopts $broadcast $norelease $dhcpopts
自动设置静态路由
如果要正常在局域网内访问单播地址,就需要将单播服务器的 IP 设置静态路由让其可以正常走 IPTV-WAN 出去,最终走到光猫 ITV 口。
用下面的脚本自动化获取 IPTV_WAN 口的 网关 地址,然后添加静态路由。
所以后续如果要添加新的静态路由,则需要编辑这个脚本里的 TARGET_NET 变量。
vim /etc/hotplug.d/iface/99-iptv-route
#!/bin/sh
set -u
[ "${INTERFACE:-}" = "IPTV_WAN" ] || exit 0
# 需要接管的单播 IP 段列表,将其替换为你自行抓包或者网络上找到的单播服务器IP
TARGET_NETS="
115.233.40.0/21
220.191.136.0/24
"
if [ "${ACTION:-}" = "ifup" ]; then
GW="$(ifstatus "$INTERFACE" | jsonfilter -e '@.inactive.route[@.target="0.0.0.0"].nexthop')"
if [ -z "$GW" ]; then
GW="$(ifstatus "$INTERFACE" | jsonfilter -e '@.data.dhcpserver')"
fi
if [ -n "$GW" ]; then
for NET in $TARGET_NETS; do
ip route replace "$NET" via "$GW" dev "$DEVICE"
logger -t IPTV_Route "Fixed: Replaced DHCP route for $NET via $GW"
done
else
logger -t IPTV_Route "Warning: Gateway not found, skip route fix"
fi
fi
主路由静态 IP 设置
为了确保在局域网内访问单播服务器时,流量走光猫的 ITV 口出去,需要在主路由上指定静态 IP 路由表,实现局域网内任意设备访问单播服务器 IP -> 静态路由到 OpenWrt -> 走 IPTV_WAN -> 光猫 ITV 口。一旦路由策略不对,导致流量走到常规公网口去了,就会出现单播无法访问的情况。
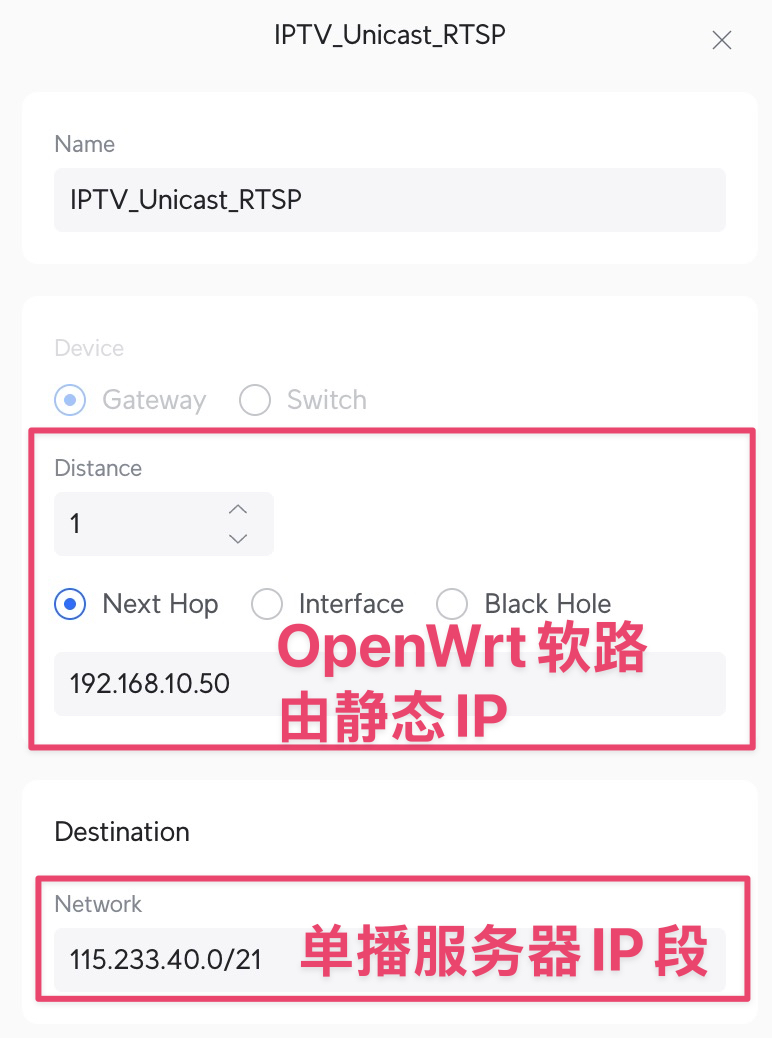
验证
以上配置全部调整好之后,重启网络以验证。注意待你重启后电脑就无法直接通过网线访问 OpenWrt 了,因为前面已经改成了主路由局域网内的 static 静态 IP,你需要将 OpenWrt 设备接入到主路由的 lan 口或者下面的交换机上面。再用你指定的静态 IP 重新访问。
重启 OpenWrt 网络:
/etc/init.d/network restart
检查 IPTV_WAN 口是否正常获取到 IP:
ifstatus IPTV_WAN
正常情况应当获取到 10 开头的 ipv4 地址。
{
"up": true,
"pending": false,
"available": true,
"autostart": true,
"dynamic": false,
"uptime": 67031,
"l3_device": "eth0.100",
"proto": "dhcp",
"device": "eth0.100",
"metric": 20,
"dns_metric": 0,
"delegation": true,
"ipv4-address": [
{
"address": "10.xxx.xxx.xxx",
"mask": 19
}
],
"dns-server": ["202.101.172.35", "202.101.172.46"],
"inactive": {
"route": [
{
"target": "0.0.0.0",
"mask": 0,
"nexthop": "10.xxx.xxx.1",
"source": "10.xxx.xxx.xxx/32"
}
]
},
"data": {
"dhcpserver": "10.xxx.xxx.1",
"leasetime": 2400
}
}
查看路由表是否生效:
ip route show
正常应当展示 /etc/hotplug.d/iface/99-iptv-route 脚本里指定的 IP 段,例如:
default via 192.168.10.1 dev br-lan metric 20
10.xxx.xxx.0/19 dev eth0.100 scope link metric 20
115.xxx.xxx.0/21 via 10.xxx.xxx.1 dev eth0.100
192.168.10.0/24 dev br-lan scope link metric 20
220.xxx.xxx.0/24 via 10.xxx.xxx.1 dev eth0.100
via 后面的 10.xxx.xxx.1 对应前面的 dhcpserver。
到这里正常情况下就大功告成了,可以在局域网内直接播放原始单播信号源。
关于 OpenWrt 支持组播信号源
在本文最前面我们没有使用 OpenWrt 也实现了正常播放组播信号,但是如果你已经有一台 OpenWrt 了,并且按照本文前面的内容进行了单播相关的设置,此时如果想同时支持组播,需要声明防火墙规则:
vi /etc/config/firewall
# --- IPTV 专用规则 ---
# 允许 UDP 组播视频流量进入,否则有信号无画面
config rule
option name 'Allow-IPTV-UDP'
option src 'wan'
option proto 'udp'
option dest_ip '224.0.0.0/4'
option target 'ACCEPT'
关于 IGMP Snooping
这个开关打开之后可能会引发一些额外的问题导致组播不可用或者卡顿。如果你没法解决则关掉最省事。
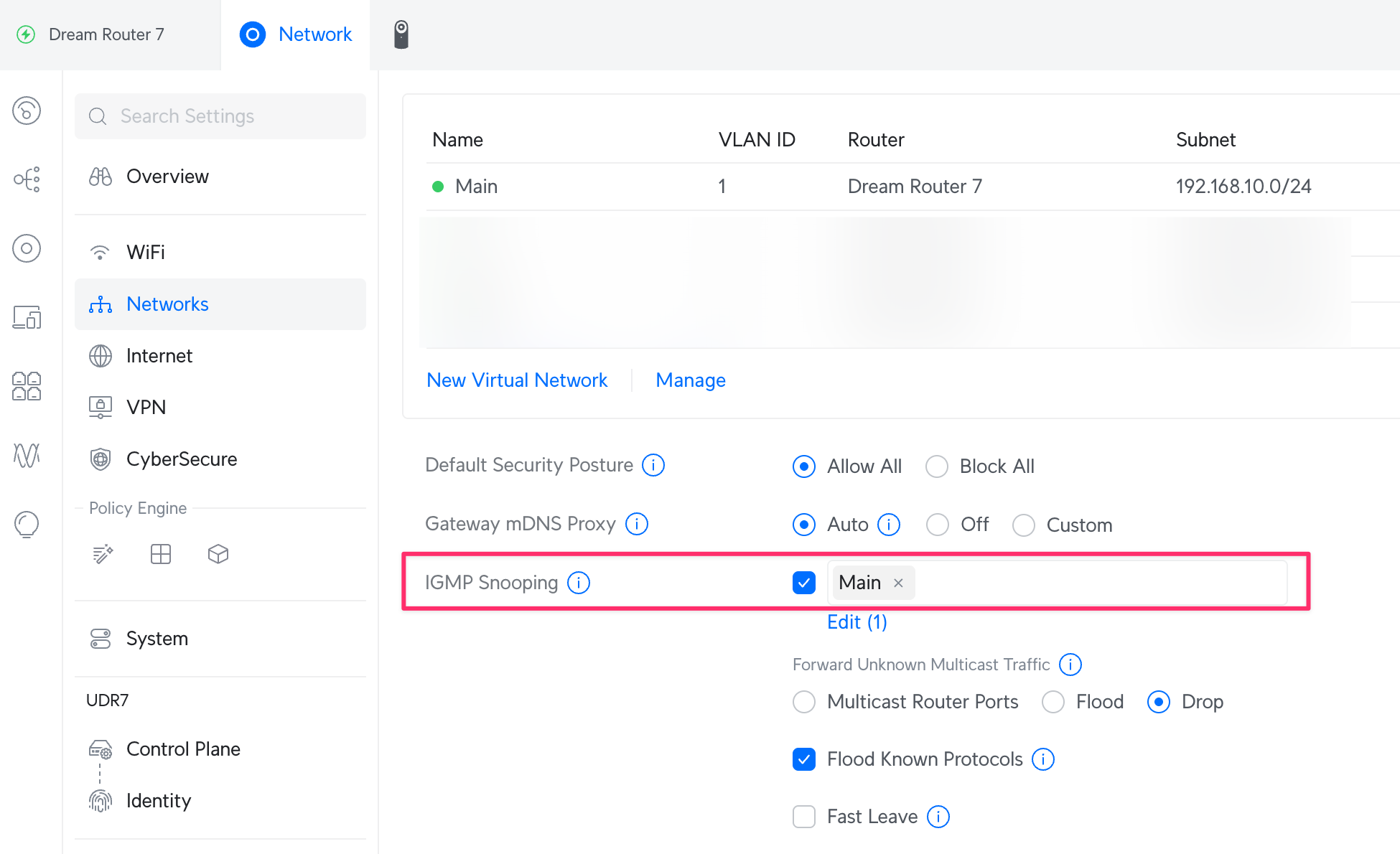
前面新建 WAN 口的时候我们开启了 IGMP Proxy,IPTV 信号成功进入了局域网(LAN),但此时如果你没有开启(或设备不支持)IGMP Snooping 就会发生“泛洪机制”。
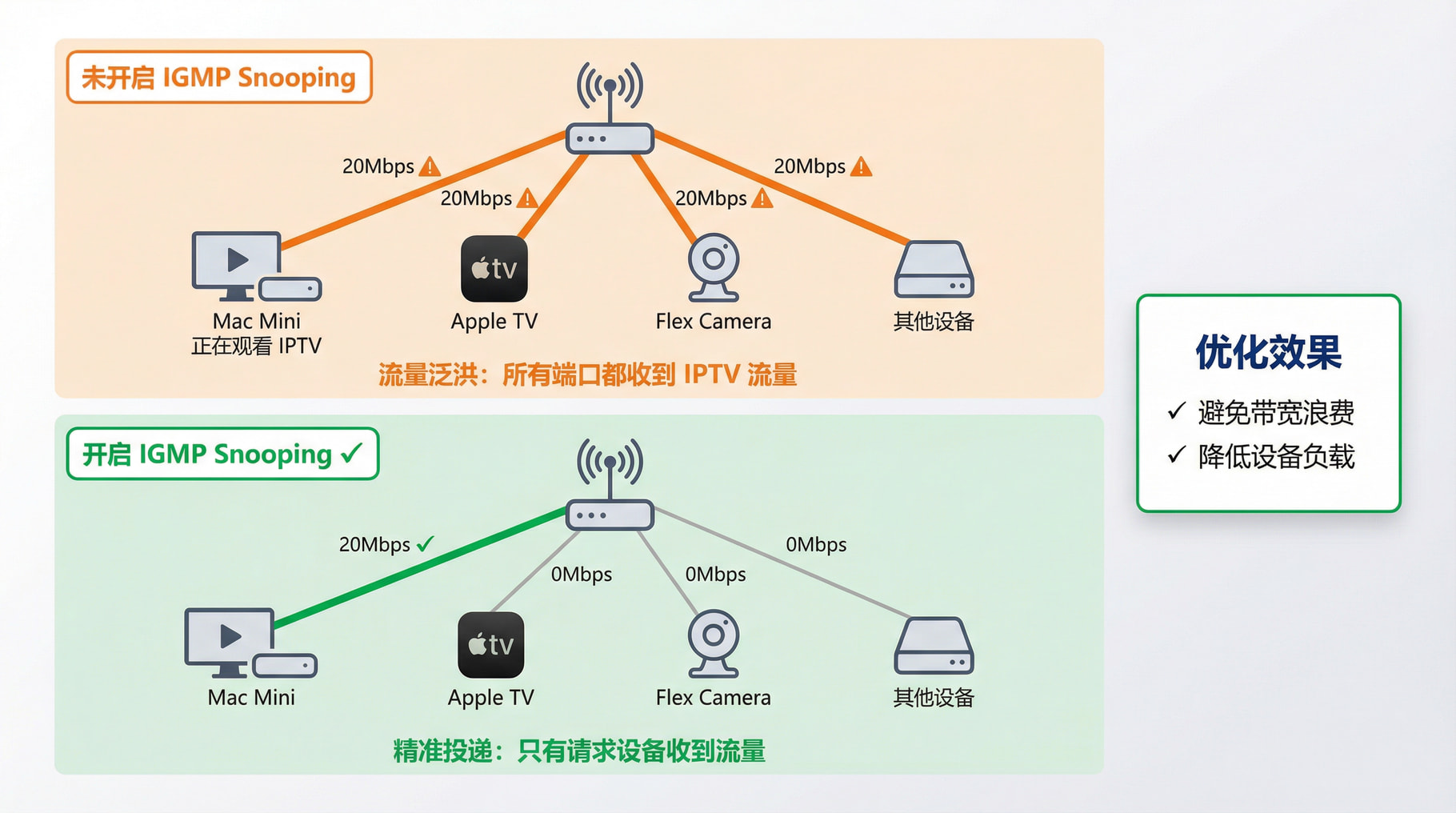
为什么会发生泛洪?
IGMPProxy 的工作(L3): 路由器把 WAN 口进来的 IPTV 视频流(比如 20Mbps 的高清流)转发到了 LAN 口。
交换机/LAN 的困惑(L2): 到了局域网这一层,普通的二层交换机(或者路由器内部集成的交换芯片)如果不运行 IGMP Snooping,它就看不懂这个组播包。
默认行为: 对于看不懂的组播包,交换机的默认处理方式是把它当成广播(Broadcast)。它会想:“我不知道谁要这个包,为了保险起见,我发给所有人吧!”
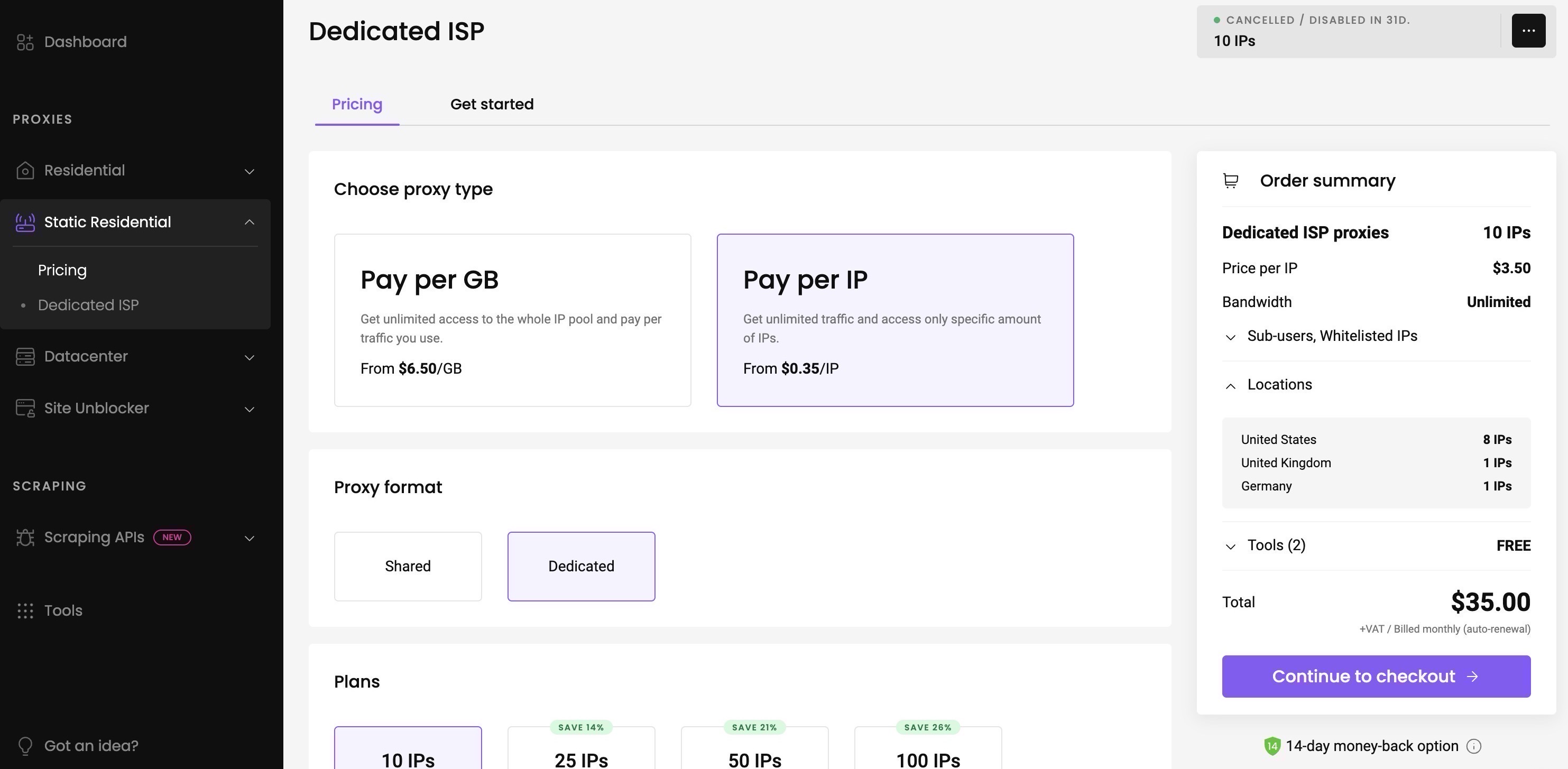
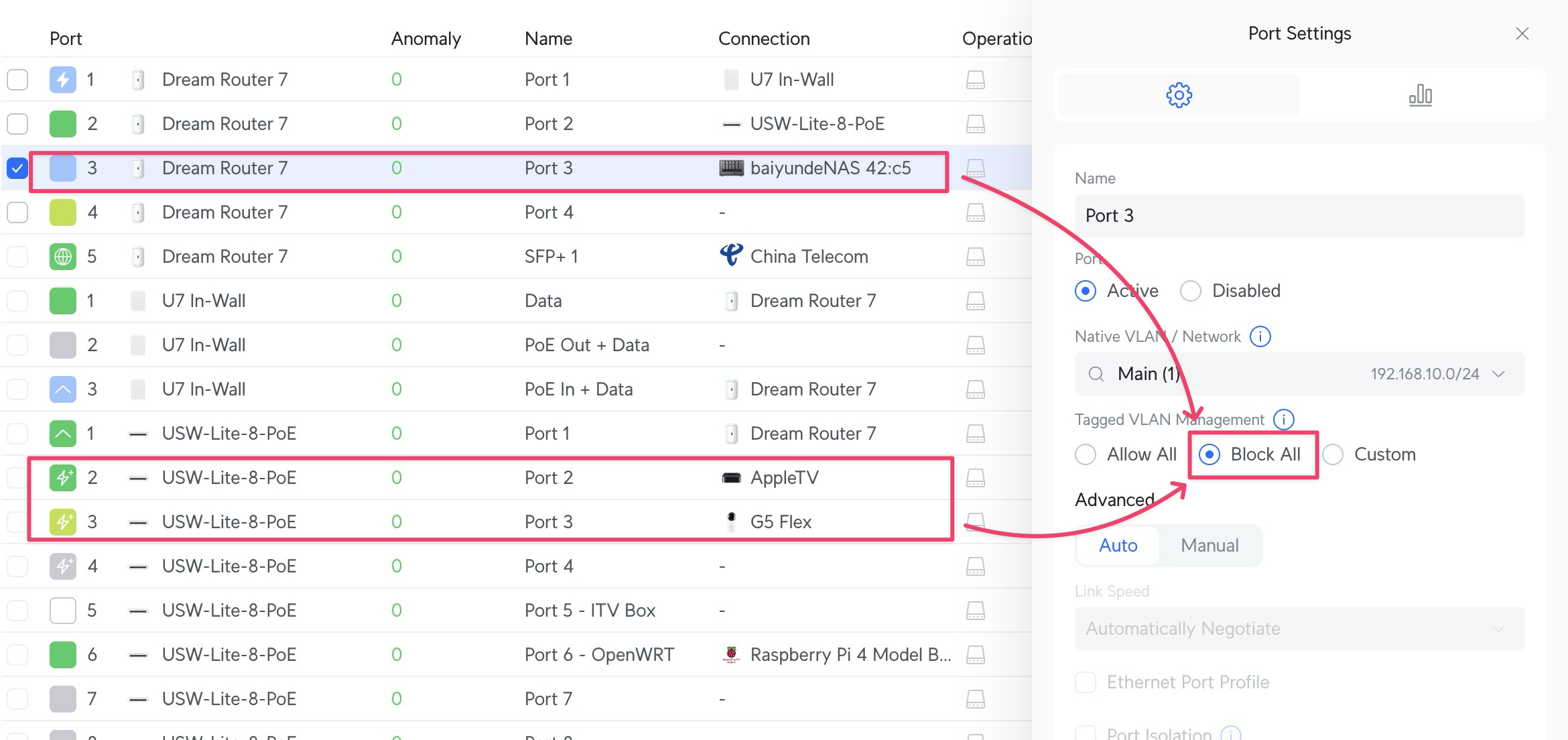
下图是局域网开启 IGMP Snooping 之前和之后的对比,注意当我在 Mac Mini 上用 APTV 观看 IPTV 频道时,Apple TV 和 Flex 摄像头的端口流量。
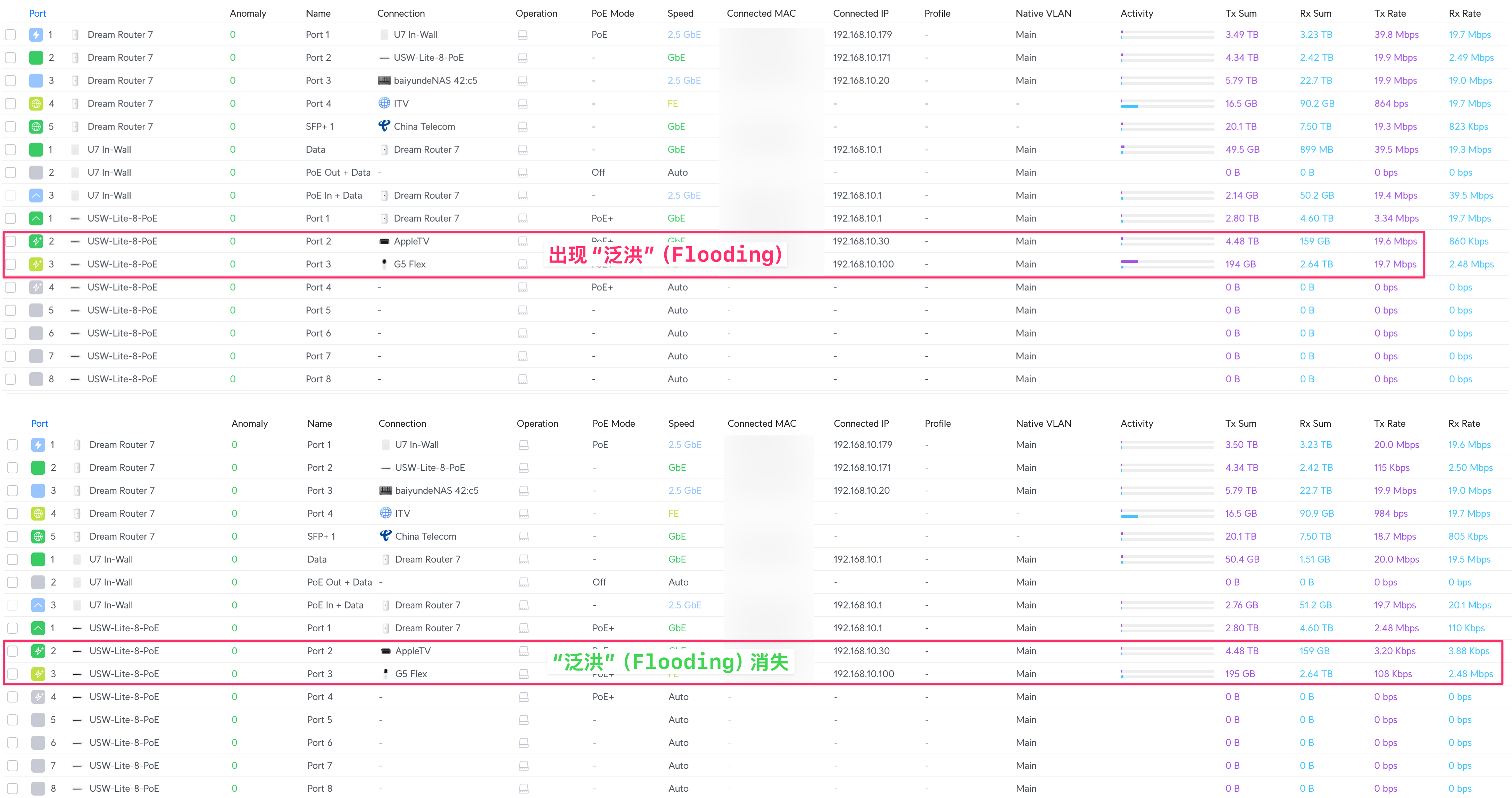
可以清晰看到,虽然我只在 Mac Mini 上观看 IPTV,但是流量被发送到了其他局域网端口(这里是 Apple TV + Flex 摄像头)。这会造成带宽和性能浪费。
IGMP Snooping 就是用来解决这个问题的。
IGMP Snooping(窥探) 是二层交换机(或桥接接口)的一个功能。它的做法: “偷听” IGMP Proxy 和机顶盒之间的对话。效果:
它听到机顶盒说:“我要看 CCTV-5”。
它就在心里记下:“只有 LAN Port 2 需要这个组播流”。
当视频流过来时,它只把数据发给 Port 2,其他端口(Port 1, 3, Wi-Fi)完全收不到这个数据。有效避免了垃圾流量产生。
OpenWrt 优化 IGMP Snooping 的副作用
IGMP Snooping 开启后如果出现无法播放或者几分钟后自动断开无信号,可以尝试将 OpenWrt 内核以及对应的 interface(在本文就是 eth.100)降低到 IGMPv2 版本。
内核层面指定使用 IGMPv2:
cat <<EOF >> /etc/sysctl.conf
# 强制 IGMP v2
net.ipv4.conf.all.force_igmp_version=2
net.ipv4.conf.eth0.100.force_igmp_version=2
EOF
sysctl -p
interface 层面也需要指定 igmp 版本:
vim /etc/config/network
找到 interface IPTV_WAN,增加一行 `option igmpversion '2':
config interface 'IPTV_WAN'
option proto 'dhcp'
option device 'eth0.100'
option metric '20'
option hostname 'xxxxxx'
option macaddr 'b1:xxxxxx'
option sendopts '60:xxxx'
option defaultroute '0'
option igmpversion '2'
不开启 IGMP Snooping 也能解决 “泛洪”
在将 OpenWrt 作为旁路由接入我的主网交换机时,我单独划分了一个 VLAN 100 给 IPTV 流量使用。其他家庭设备不会接入这个 VLAN。
所以呢,我们完全可以在 VLAN 层面切断 “泛洪”,具体做法是,在其他连接局域网设备的 LAN 口上只接受一个 Main VLAN(家里主局域网),其他 VLAN 流量一律屏蔽即可解决 “泛洪” 的问题。
路由器到 AP 的端口设置为自定义 VLAN,以确保访客和 IoT 设备专用 Wi-Fi 可以正常使用。
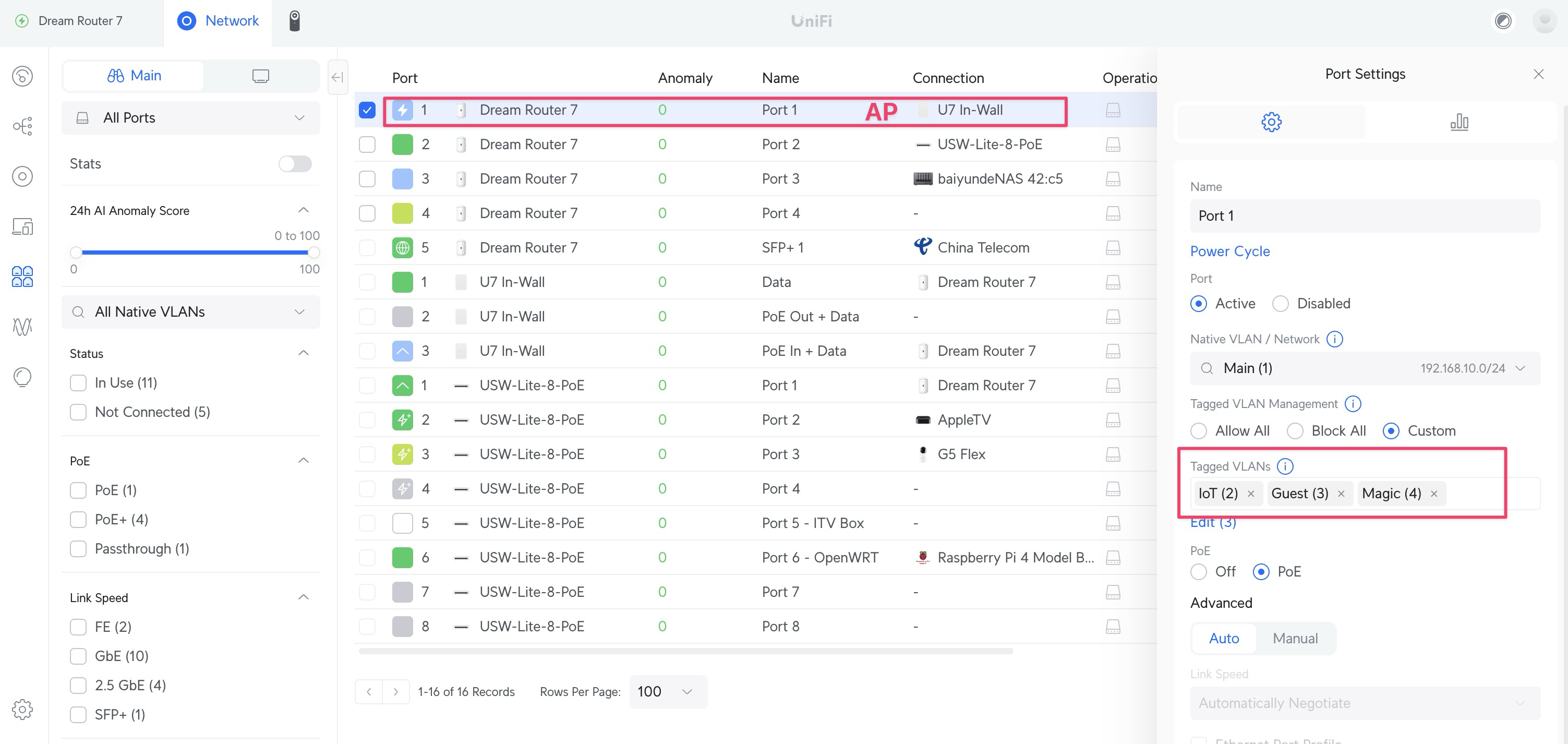
其他连接 NAS 和局域网设备的端口一律设置为 Block all,这样 IPTV 的组播流量由于有 vlan id = 100 的标记,就不会影响到其他 VLAN 端口。
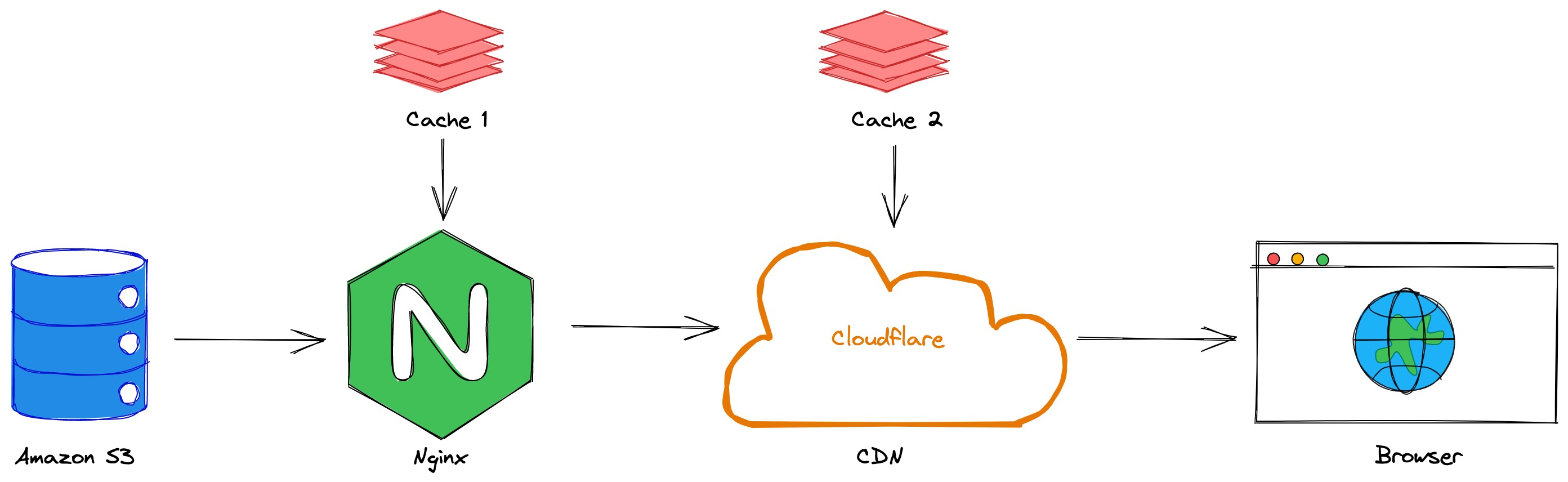
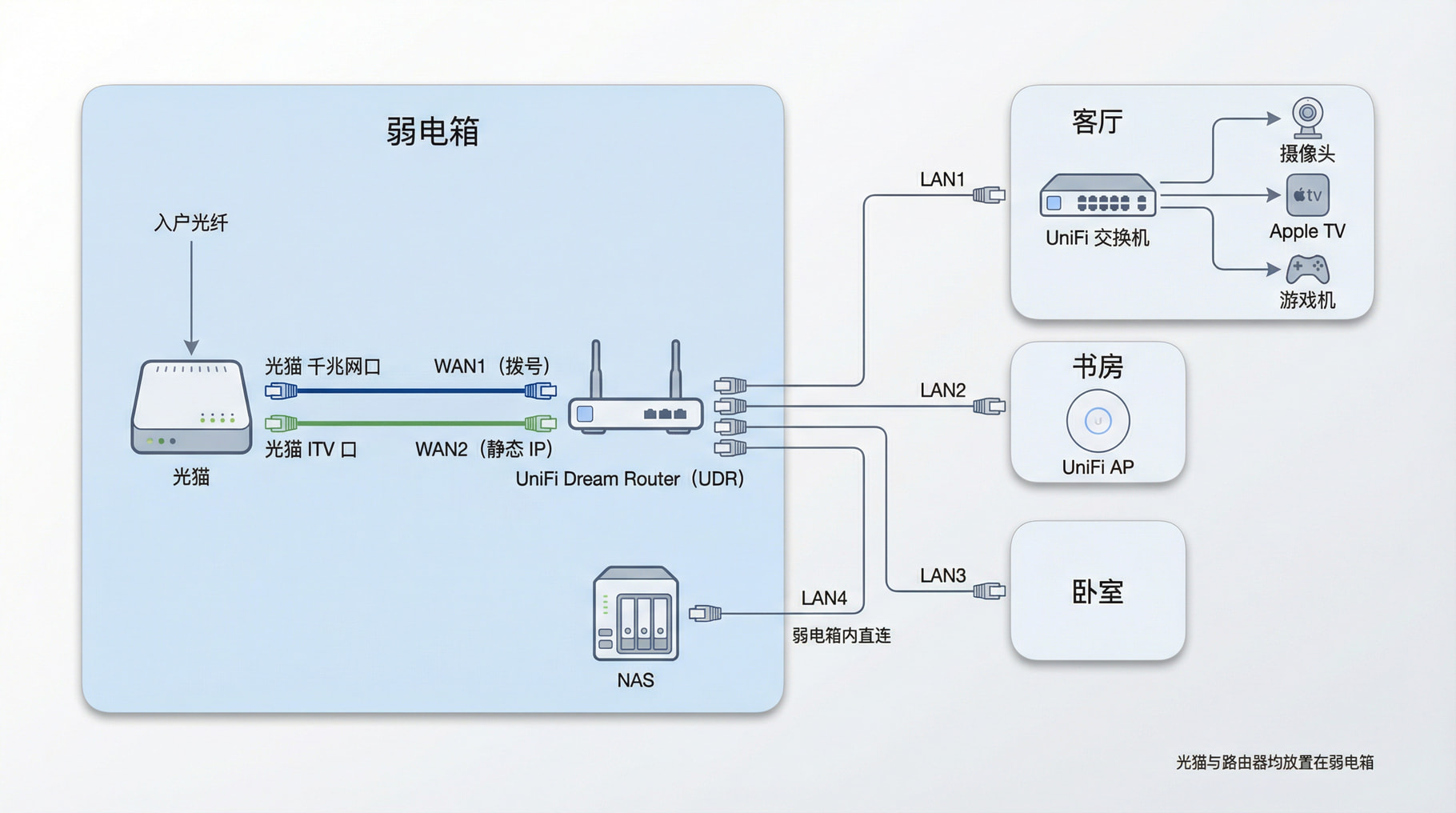
本文网络拓扑参考
组播转单播
如果你只是组播转单播,这个架构就足够了
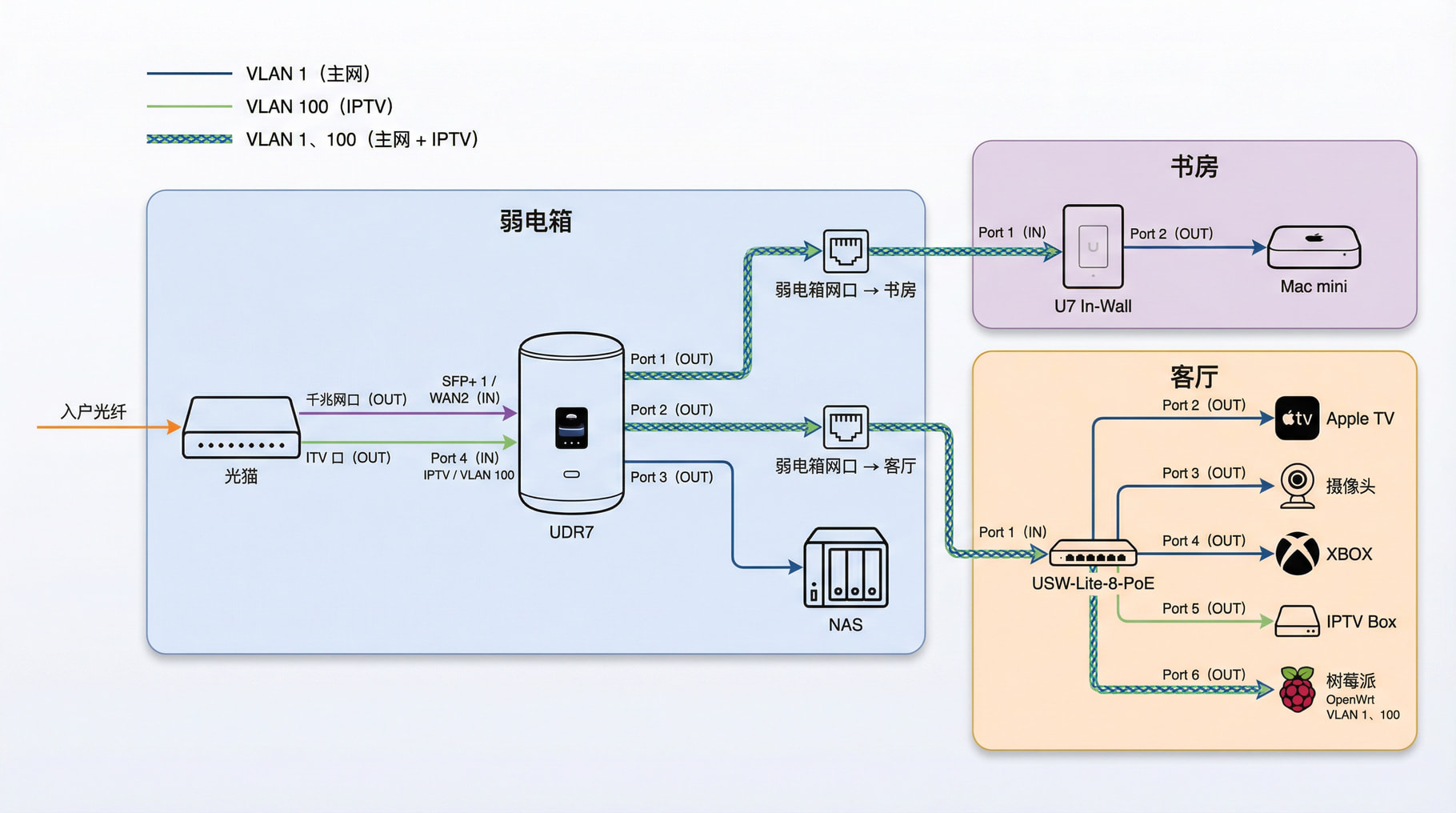
原始单播
为了正常访问原始单播信号源,网络架构变的复杂了很多。下面这个架构同时支持原始单播和组播。
引入了 VLAN + Trunk:核心功能是通过单条网线/端口承载和传输来自多个 VLAN 的流量,通过 VLAN 标记(如802.1Q)区分不同 VLAN 的帧。
总结
本文提供了两种方案,其中组播方案唯一的物理链路修改是光猫到路由器多了一根网线,客厅网口和 HDMI 线完全没有任何调整。
原始单播方案引入了额外的 OpenWrt 旁路由,整体网络配置方案较为复杂。
两种方案都可以实现在任意局域网设备例如 Apple TV 上观看 IPTV 节目,整体具备低延迟高稳定性。
折腾下来可以明显感知到 IPTV 在技术和电信资源层面明显是要比互联网流媒体占很大优势的,可惜在内容方面惨不忍睹,白白浪费这些电信资源。
踩坑需要耗费不少时间,如果此文对你有帮助,欢迎通过 /buyMeCoffee 请我喝杯咖啡。
相关参考资源
感谢诸多在互联网上公开分享自己折腾历程的人。
- 查看杭州电信支持的 IPTV 频道列表:https://myepg.org/Zhejiang_Hangzhou_Telecom_IPTV/report.html
- https://github.com/luckyyyyy/blog/issues/75
- https://www.right.com.cn/forum/thread-794304-1-1.html
- https://luolei.org/chinanet-iptv
- https://nga.178.com/read.php?tid=39800789
要获得最佳阅读体验,请访问原文 https://baiyun.me/zhejiang-hangzhou-telecom-iptv]]>